The Dominion of Pinterest
Published: Thursday, May 18, 2023Last Modified: Sunday, July 14, 2024

Table of Contents
Introduction
I recently noticed there's too many images search results for Pinterest in DuckDuckGo. Too many. It's like their unofficial front end.
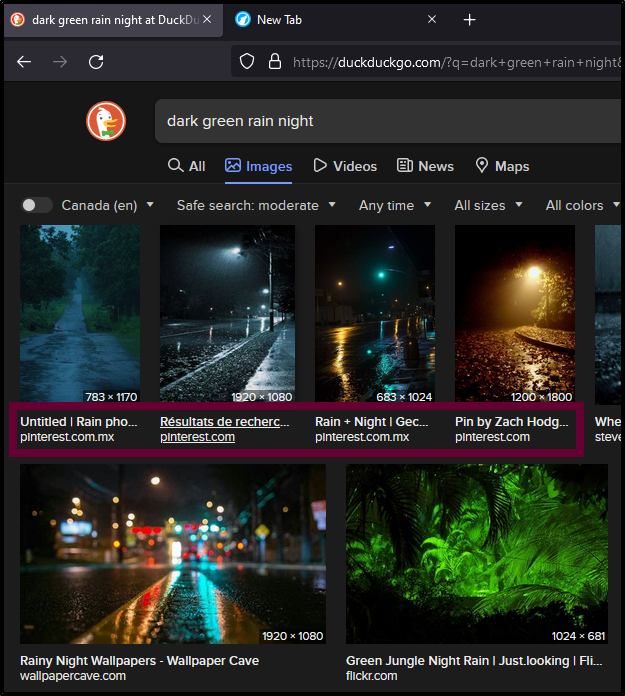
This made me feel uneasy for three reasons.
- I don't value the content on that site, it seems like the bulk of it is recycled material.
- One site shouldn't have that much of a presence in my search results.
- I should be able to remove it from my home network, but how?
Before going any further, let's see if my gut instinct is correct, or if I am fixated on nothing. Let's see just how many images are related to a Pinterest domain when we search for dark green rain night.
Analysis
Saving the html of each search engine's results into its own file...

Writing the Python script to do our bidding...
from bs4 import BeautifulSoup
from collections import Counter
html_files = ['DuckDuckGo.html', 'Google.html', 'Searx.html']
for html_file in html_files:
print(f'## {html_file} ##')
with open(html_file, mode='r', encoding='utf-8') as f:
soup = BeautifulSoup(f.read(), 'html.parser')
# these parsing rules may be different for you
if 'DuckDuckGo' in html_file:
domains = [elem.text for elem in soup.find_all('span', class_='tile--img__domain')]
elif 'Google' in html_file:
domains = [elem.get('href').strip('https://').split('/')[0] for elem in soup.find_all('a', attrs={'jsname': 'uy6ald'})]
elif 'Searx' in html_file:
domains = [elem.find('a').get('href').strip('https://').split('/')[0] for elem in soup.find_all('div', class_='result result-images google images js')]
else:
raise ValueError(html_file)
if domains == []: raise ValueError(domains)
# getting host names
for i, domain in enumerate(domains):
domain_type = domain.count('.')
domain = domain.replace('.co.', '.') # 'pinterest.co.uk'
domain_type = domain.count('.')
if domain_type >= 3:
host_name = domain.split('.')[-2] # www.cus.workers.dev
elif domain_type == 2:
host_name = domain.split('.')[1] # www.usa.com
elif domain_type == 1:
host_name = domain.split('.')[0] # usa.com
elif domain_type == 0:
host_name = domain # usa
else:
raise ValueError(domain)
domains[i] = host_name
# analysis
domains_count = len(domains)
print(f'Domain Count: {domains_count}')
print(f'Domain Distinct Count: {len(set(domains))}')
header = f"{'Fraction (%)':<12} | {'Count':<5} | Domain"
print(header)
print('-' * len(header))
for domain, count in Counter(domains).most_common(15):
print(f'{round((count / domains_count) * 100, 1):<12} | {count:<5} | {domain}')
print()
That was fairly straightforward... I scanned all the domains manually to make sure nothing was labelled incorrectly.
Results
## DuckDuckGo.html ##
Domain Count: 469
Domain Distinct Count: 125
Fraction (%) | Count | Domain
-----------------------------
20.5 | 96 | pinterest # Oh no no no....
10.2 | 48 | dreamstime
6.0 | 28 | blogspot
4.5 | 21 | flickr
3.4 | 16 | pxhere
3.2 | 15 | wallpapercave
3.0 | 14 | wallhere
2.8 | 13 | youtube
2.6 | 12 | shutterstock
2.1 | 10 | papers
1.7 | 8 | wallpaperaccess
1.7 | 8 | reddit
1.7 | 8 | deviantart
1.5 | 7 | mixkit
1.3 | 6 | wallpapersafari
## Google.html ##
Domain Count: 298
Domain Distinct Count: 92
Fraction (%) | Count | Domain
-----------------------------
5.4 | 16 | pinterest
4.7 | 14 | alamy
4.4 | 13 | dreamstime
4.4 | 13 | freepik
4.0 | 12 | shutterstock
4.0 | 12 | vecteezy
4.0 | 12 | youtube
3.4 | 10 | 123rf
3.0 | 9 | unsplash
2.7 | 8 | istockphoto
2.7 | 8 | pxfuel
2.7 | 8 | prompthunt
2.3 | 7 | peakpx
2.0 | 6 | pond5
2.0 | 6 | rare-gallery
## Searx.html ##
Domain Count: 380
Domain Distinct Count: 147
Fraction (%) | Count | Domain
-----------------------------
3.9 | 15 | pinimg
3.7 | 14 | unsplash
3.7 | 14 | istockphoto
3.2 | 12 | freepik
2.9 | 11 | dreamstime
2.9 | 11 | alamy
2.6 | 10 | 123rf
2.6 | 10 | shopify
2.4 | 9 | pxfuel
2.4 | 9 | shutterstock
2.4 | 9 | vecteezy
2.1 | 8 | ytimg
1.8 | 7 | peakpx
1.8 | 7 | depositphotos
1.8 | 7 | media-amazonMy primary search engine has been DuckDuckGo for a while now, and so this explains why I see so much Pinterest.
IT'S A TOTAL PINTEREST DOMINION !

Pinterest is in an invasive species, casting foreboding shadows over too much of the internet's landscape, including authentic, soulful websites.
Counter Measures
What can we do about the Pinterest menace? It's in every search engine, too far and too wide.
We could add -site: "pinterest" to each of our search queries, but that's a huge hassle.
We could use AdGuard Home to block the son-of-a-bitch! YEAH, OKAY!
I got AdGuard Home working on a Vultr VPS by following these steps,
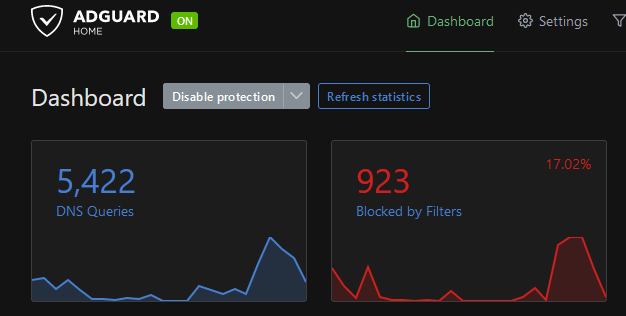
I blocked The Dominion.
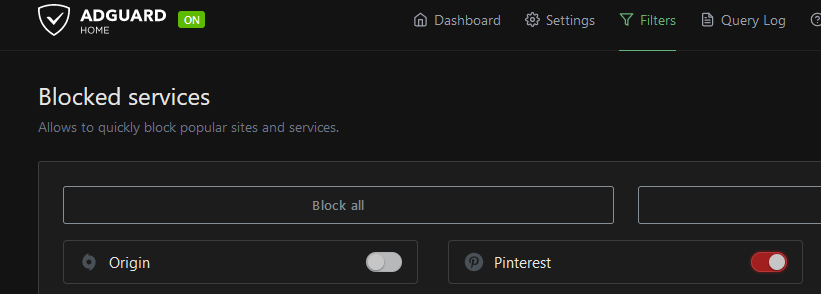

And that's when I learned that while AdGuard blocks you from *visiting* certain websites, it cannot filter out search engine results. The images arrive to the browser in base64, or so they say. What a sorry state of affairs that is. They should market AdGuard Home as a product that's only useful to impose parental controls.
A last-ditch attempt was given using uBlacklist. To my surprise, it actually worked with Google and Searx!
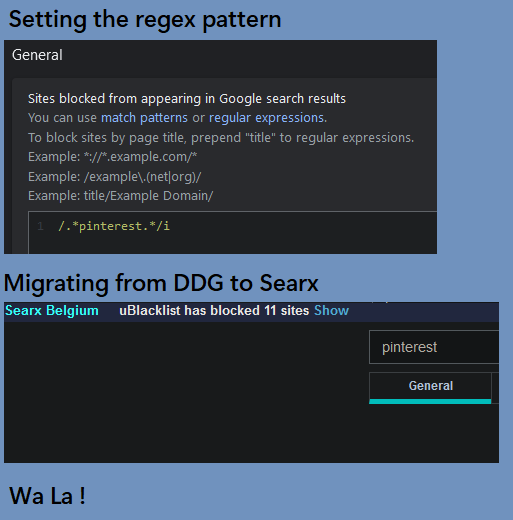
The downside is that it's currently not working with DuckDuckGo, and it's not available through Mozilla FireFox's (Android) select few Add-ons. At the time of writing this, Mozilla only has 18 Add-ons for FireFox Android, and as far as I am aware, it is the only browser for Android that offers any add-ons.
Conclusion
I am still trying to find ways of blocking a website from my home network, and on my phone when I am away from home -- not just on my desktop's browser. Partial site blocking, like what AdGuard Home offers, is not close to achieving what I want. uBlacklist reaches closer to my objective. I am aware of the concept of "Enumerating the Bad", but I still think I should be able to choose what websites are not allowed to permeate my home network. If you have any ideas on how to accomplish this, please let me know in the comments on my homepage. I'd appreciate it.